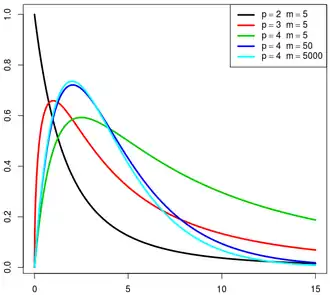
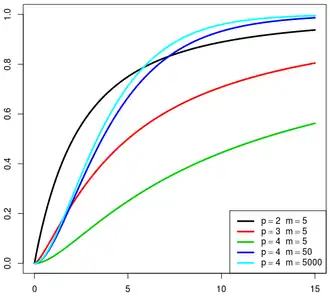
In statistics, particularly in hypothesis testing, the Hotelling's T-squared distribution (T2), proposed by Harold Hotelling,[1] is a multivariate probability distribution that is tightly related to the F-distribution and is most notable for arising as the distribution of a set of sample statistics that are natural generalizations of the statistics underlying the Student's t-distribution.
The Hotelling's t-squared statistic (t2) is a generalization of Student's t-statistic that is used in multivariate hypothesis testing.[2]
Motivation
The distribution arises in multivariate statistics in undertaking tests of the differences between the (multivariate) means of different populations, where tests for univariate problems would make use of a t-test.
The distribution is named for Harold Hotelling, who developed it as a generalization of Student's t-distribution.[1]
Definition
If the vector  is Gaussian multivariate-distributed with zero mean and unit covariance matrix
is Gaussian multivariate-distributed with zero mean and unit covariance matrix  and
and  is a
is a  random matrix with a Wishart distribution
random matrix with a Wishart distribution  with unit scale matrix and m degrees of freedom, and d and M are independent of each other, then the quadratic form
with unit scale matrix and m degrees of freedom, and d and M are independent of each other, then the quadratic form  has a Hotelling distribution (with parameters
has a Hotelling distribution (with parameters  and
and  ):[3]
):[3]

It can be shown that if a random variable X has Hotelling's T-squared distribution,  , then:[1]
, then:[1]

where  is the F-distribution with parameters p and m − p + 1.
is the F-distribution with parameters p and m − p + 1.
Hotelling t-squared statistic
Let  be the sample covariance:
be the sample covariance:

where we denote transpose by an apostrophe. It can be shown that is a positive (semi) definite matrix and  follows a p-variate Wishart distribution with n − 1 degrees of freedom.[4]
The sample covariance matrix of the mean reads
follows a p-variate Wishart distribution with n − 1 degrees of freedom.[4]
The sample covariance matrix of the mean reads  .[5]
.[5]
The Hotelling's t-squared statistic is then defined as:[6]

which is proportional to the Mahalanobis distance between the sample mean and  . Because of this, one should expect the statistic to assume low values if
. Because of this, one should expect the statistic to assume low values if  , and high values if they are different.
, and high values if they are different.
From the distribution,

where  is the F-distribution with parameters p and n − p.
is the F-distribution with parameters p and n − p.
In order to calculate a p-value (unrelated to p variable here), note that the distribution of  equivalently implies that
equivalently implies that

Then, use the quantity on the left hand side to evaluate the p-value corresponding to the sample, which comes from the F-distribution. A confidence region may also be determined using similar logic.
Motivation
Let  denote a p-variate normal distribution with location and known covariance
denote a p-variate normal distribution with location and known covariance  . Let
. Let

be n independent identically distributed (iid) random variables, which may be represented as  column vectors of real numbers. Define
column vectors of real numbers. Define

to be the sample mean with covariance  . It can be shown that
. It can be shown that

where  is the chi-squared distribution with p degrees of freedom.[7]
is the chi-squared distribution with p degrees of freedom.[7]
Proof
|
|
Alternatively, one can argue using density functions and characteristic functions, as follows.
Proof
To show this use the fact that  and derive the characteristic function of the random variable
and derive the characteristic function of the random variable  . As usual, let . As usual, let  denote the determinant of the argument, as in denote the determinant of the argument, as in  . .
By definition of characteristic function, we have:[8]
![{\displaystyle {\begin{aligned}\varphi _{\mathbf {y} }(\theta )&=\operatorname {E} e^{i\theta \mathbf {y} },\\[5pt]&=\operatorname {E} e^{i\theta ({\overline {\mathbf {x} }}-{\boldsymbol {\mu }})'({\mathbf {\Sigma } }/n)^{-1}({\overline {\mathbf {x} }}-{\boldsymbol {\mathbf {\mu } }})}\\[5pt]&=\int e^{i\theta ({\overline {\mathbf {x} }}-{\boldsymbol {\mu }})'n{\mathbf {\Sigma } }^{-1}({\overline {\mathbf {x} }}-{\boldsymbol {\mathbf {\mu } }})}(2\pi )^{-p/2}|{\boldsymbol {\Sigma }}/n|^{-1/2}\,e^{-(1/2)({\overline {\mathbf {x} }}-{\boldsymbol {\mu }})'n{\boldsymbol {\Sigma }}^{-1}({\overline {\mathbf {x} }}-{\boldsymbol {\mu }})}\,dx_{1}\cdots dx_{p}\end{aligned}}}](./_assets_/f4f7443b5a91e8899f181974528a7d34bf9e047a.svg)
There are two exponentials inside the integral, so by multiplying the exponentials we add the exponents together, obtaining:

Now take the term  off the integral, and multiply everything by an identity off the integral, and multiply everything by an identity  , bringing one of them inside the integral: , bringing one of them inside the integral:

But the term inside the integral is precisely the probability density function of a multivariate normal distribution with covariance matrix ![{\displaystyle ({\boldsymbol {\Sigma }}^{-1}-2i\theta {\boldsymbol {\Sigma }}^{-1})^{-1}/n=\left[n({\boldsymbol {\Sigma }}^{-1}-2i\theta {\boldsymbol {\Sigma }}^{-1})\right]^{-1}}](./_assets_/b2e30acda26292ba3fcf5d6d302141d34fcebce5.svg) and mean and mean  , so when integrating over all , so when integrating over all  , it must yield , it must yield  per the probability axioms. We thus end up with: per the probability axioms. We thus end up with:
![{\displaystyle {\begin{aligned}&=\left|({\boldsymbol {\Sigma }}^{-1}-2i\theta {\boldsymbol {\Sigma }}^{-1})^{-1}\cdot {\frac {1}{n}}\right|^{1/2}|{\boldsymbol {\Sigma }}/n|^{-1/2}\\&=\left|({\boldsymbol {\Sigma }}^{-1}-2i\theta {\boldsymbol {\Sigma }}^{-1})^{-1}\cdot {\frac {1}{\cancel {n}}}\cdot {\cancel {n}}\cdot {\boldsymbol {\Sigma }}^{-1}\right|^{1/2}\\&=\left|\left[({\cancel {{\boldsymbol {\Sigma }}^{-1}}}-2i\theta {\cancel {{\boldsymbol {\Sigma }}^{-1}}}){\cancel {\boldsymbol {\Sigma }}}\right]^{-1}\right|^{1/2}\\&=|\mathbf {I} _{p}-2i\theta \mathbf {I} _{p}|^{-1/2}\end{aligned}}}](./_assets_/d7b99da9756cc4c6b0312d41367697e0aa53eaca.svg)
where  is an identity matrix of dimension . Finally, calculating the determinant, we obtain: is an identity matrix of dimension . Finally, calculating the determinant, we obtain:

which is the characteristic function for a chi-square distribution with degrees of freedom. 
|
Two-sample statistic
If  and
and  , with the samples independently drawn from two independent multivariate normal distributions with the same mean and covariance, and we define
, with the samples independently drawn from two independent multivariate normal distributions with the same mean and covariance, and we define

as the sample means, and


as the respective sample covariance matrices. Then

is the unbiased pooled covariance matrix estimate (an extension of pooled variance).
Finally, the Hotelling's two-sample t-squared statistic is

It can be related to the F-distribution by[4]

The non-null distribution of this statistic is the noncentral F-distribution (the ratio of a non-central Chi-squared random variable and an independent central Chi-squared random variable)

with

where  is the difference vector between the population means.
is the difference vector between the population means.
In the two-variable case, the formula simplifies nicely allowing appreciation of how the correlation,  ,
between the variables affects . If we define
,
between the variables affects . If we define

and

then
![{\displaystyle t^{2}={\frac {n_{x}n_{y}}{(n_{x}+n_{y})(1-\rho ^{2})}}\left[\left({\frac {d_{1}}{s_{1}}}\right)^{2}+\left({\frac {d_{2}}{s_{2}}}\right)^{2}-2\rho \left({\frac {d_{1}}{s_{1}}}\right)\left({\frac {d_{2}}{s_{2}}}\right)\right]}](./_assets_/98484fd561e69c414a3091e297e110b4c75fda03.svg)
Thus, if the differences in the two rows of the vector  are of the same sign, in general, becomes smaller as becomes more positive. If the differences are of opposite sign becomes larger as becomes more positive.
are of the same sign, in general, becomes smaller as becomes more positive. If the differences are of opposite sign becomes larger as becomes more positive.
A univariate special case can be found in Welch's t-test.
More robust and powerful tests than Hotelling's two-sample test have been proposed in the literature, see for example the interpoint distance based tests which can be applied also when the number of variables is comparable with, or even larger than, the number of subjects.[9][10]
See also
References
- ^ a b c Hotelling, H. (1931). "The generalization of Student's ratio". Annals of Mathematical Statistics. 2 (3): 360–378. doi:10.1214/aoms/1177732979.
- ^ Johnson, R.A.; Wichern, D.W. (2002). Applied multivariate statistical analysis. Vol. 5. Prentice hall.
- ^ Eric W. Weisstein, MathWorld
- ^ a b Mardia, K. V.; Kent, J. T.; Bibby, J. M. (1979). Multivariate Analysis. Academic Press. ISBN 978-0-12-471250-8.
- ^ Fogelmark, Karl; Lomholt, Michael; Irbäck, Anders; Ambjörnsson, Tobias (3 May 2018). "Fitting a function to time-dependent ensemble averaged data". Scientific Reports. 8 (1): 6984. doi:10.1038/s41598-018-24983-y. PMC 5934400. Retrieved 19 August 2024.
- ^ "6.5.4.3. Hotelling's T squared".
- ^ End of chapter 4.2 of Johnson, R.A. & Wichern, D.W. (2002)
- ^ Billingsley, P. (1995). "26. Characteristic Functions". Probability and measure (3rd ed.). Wiley. ISBN 978-0-471-00710-4.
- ^ Marozzi, M. (2016). "Multivariate tests based on interpoint distances with application to magnetic resonance imaging". Statistical Methods in Medical Research. 25 (6): 2593–2610. doi:10.1177/0962280214529104. PMID 24740998.
- ^ Marozzi, M. (2015). "Multivariate multidistance tests for high-dimensional low sample size case-control studies". Statistics in Medicine. 34 (9): 1511–1526. doi:10.1002/sim.6418. PMID 25630579.
External links
|
|---|
Discrete
univariate | with finite
support | |
|---|
with infinite
support | |
|---|
|
|---|
Continuous
univariate | supported on a
bounded interval | |
|---|
supported on a
semi-infinite
interval | |
|---|
supported
on the whole
real line | |
|---|
with support
whose type varies | |
|---|
|
|---|
Mixed
univariate | |
|---|
Multivariate
(joint) | |
|---|
| Directional | |
|---|
Degenerate
and singular | |
|---|
| Families | |
|---|
|







![{\displaystyle {\begin{aligned}\operatorname {var} \left(\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}{\overline {\boldsymbol {x}}}\right)&=\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}{\Big (}\operatorname {var} \left({\overline {\boldsymbol {x}}}\right){\Big )}\left(\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}\right)^{T}\\[5pt]&=\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}{\Big (}\operatorname {var} \left({\overline {\boldsymbol {x}}}\right){\Big )}\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}{\text{ because }}\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}{\text{ is symmetric}}\\[5pt]&=\left(\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{1/2}\right)\left(\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{1/2}\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}\right)\\[5pt]&=\mathbf {I} _{p}.\end{aligned}}}](./_assets_/233c43eefadbcf9abcdff40e73cff853019bee5e.svg)


